
5

Tags:
databaser

Skrevet af
Bruger #2730
@ 23.05.2003
Denne artikel er starten på en artikelserie om hvordan man kan bygge en simpel kube ved at bruge Microsoft Analysis Services, der er en del af Microsoft SQL Server 2000. Før artiklen startes er det vigtigt at have SQL Server 2000 installeret med minimum service pack 2, samt Analysis Services komponenten også med minimum service pack 2 (bemærk at der kan være nogle problemer hvis ikke de to komponenter har samme version).
Den relationelle databaseDet første der skal gøres klar er den relationelle database, i den forbindelse er det utroligt vigtigt at man har styr på sine dimensionstabeller da det er dem der er afgørende for hvor meget data der kommer med i kuben. Det lyder måske lidt kryptisk på nuværende tidspunkt, men det skal jeg nok forklare senere. For det første må der ikke være dubletter i dimensionstabellen, det vil sige at samme nøgle må ikke findes to gange på dimensionstabellen, da dette vil multiplicere værdierne for den nøgle der er dobbelt med to (hvis nøglen findes to gange på dimensionstabellen). Dette er ikke hensigtsmæssigt, da data for denne dimensionsværdi vil være forkerte. Nedenstående er et eksempel på en korrekt dimensionstabel, samt en forkert dimensionstabel.
En korrekt dimensionstabel, indeholdende kun een værdi af hver nøgle mod fact tabellen.
Fact tabel (bogsalg)
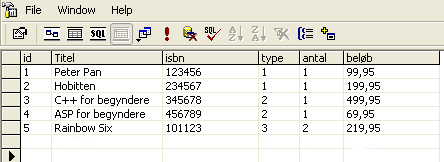
Dimensionstabel (typer)
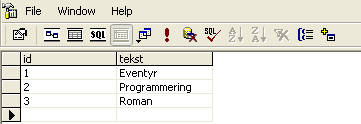
En forkert dimensionstabel hvor der er dubletter vil se ud som nedenstående. Bemærk dubletter i dimensionstabellen.
Fact tabel (bogsalg)
Dimensionstabel (typer)
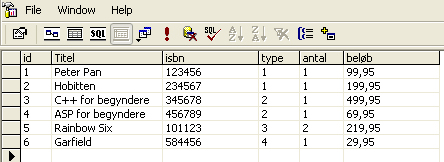
Den forkerte dimensionstabel vil reelt gøre, at rækkerne (tuplerne) i fact tabellen vil blive multipliceret med to, boghandelen vil sikkert blive imponeret over hvor meget de har solgt, men det varer kun til de ser i regnskaberne, så står database udvikleren og skal finde nyt job! Rent faktisk vil det se ud til at de har solgt 4 bøger med typen programmering og have tjent dobbelt så meget som de reelt har. Efter denne oplevelse vil boghandelen ikke længe kunne stole på de data der bliver vist i det data warehouse database udvikleren har udviklet, dette er langt fra en optimal situation. Derfor skal man altid sørge for at der kun er een værdi i dimensionstabellen for hver enkelt værdi i fact tabellen. Det fænomen med forkerte dimensionstabeller kaldes inkonsistens, det vil sige at dataene i fact tabellen og dimensionstabellen ikke er sammenhængende. Det eksempel der lige har været gennemgået viser hvad der sker hvis der er dubletter i dimensionstabellen, men hvad nu hvis man forestilte sig, at der manglede værdier i dimensionstabellen.
Fact tabel (bogsalg)
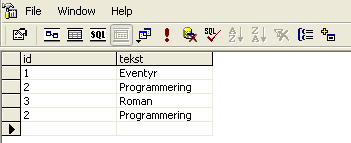
Dimensionstabel (typer)
I ovenstående situation mangler der værdier i dimensionstabellen, dette skyldes enten at programmøren har sløset da han udviklede programmet, eller så tager systemet simpelthen ikke højde for at denne uhensigtsmæssighed skal udbedres, det vil sige at der ikke laves konsistenskontrol. Dette tilfælde skal man som database udvikler også tage højde for. Hvis man sammenligner med den forkerte fact tabel fra forrige eksempel, hvor vi fik for mange solgte bøger da der var redundans i vores dimensionstabel, oplever vi nu det modsatte, nemlig at bogen ”Garfield” ikke kommer med i vores kube da der ikke findes en sammenhæng mellem fact tabellen og dimensionstabellen. Måden at løse det første problem på er ved at lave en ny dimensionstabel, hvori man indsætter unikke nøgler fra fact tabellen. Dette kan gøres ved følgende SQL statement:
insert into dim_typer(id, type_tekst)
select distinct type from bogsalg
go
Dette vil medføre at man får samtlige unikke typer fra fact tabellen indsat I den nye dimensionstabel der hedder dim_typer. Denne måde har så ulempen at man efterfølgende skal ind og lave nogle update statements der tager højde for tomme værdier, samt opdaterer dimensionstabellen med teksten for typerne:
update dim_typer set dim_type_tekst = ’Eventyr’ where id = 1
update dim_typer set dim_type_tekst = ’Programmering’ where id = 2
update dim_typer set dim_type_tekst = ’Roman’ where id = 3
update dim_typer set dim_type_tekst = ’Tegneserie’ where id = 4
update dim_typer set tekst = ’N/A’ where tekst is null
go
Ovenstående kode opdaterer dimensionstabellen med de korrekte tekster, da vi ved vores ”select distinct” statement kun fandt nøglerne fra fact tabellen, men ikke værdierne. Værdierne/teksten indsætter vi så efterfølgende manuelt ved disse update statements. Den sidste update statement tager højde for de ting vi ikke ved, det vil sige at alle de værdier der ikke er blevet opdateret med nogen tekst får værdien N/A. Dette lille trick giver to ting, eet vi kan altid finde de værdier der ikke har fået navn og så tilføje nogle ekstra updates til vores update statements og få lappet hullerne på den måde. Den anden fordel er at vi i vores kube får vist data grupperet på en ”N/A” type, dette giver en bedre oplevelse for brugeren istedet for at der ikke er nogen tekst, men dette er mere psykologi end det er godt for modelleringen. Det mest optimale man kan gøre er simpelthen at lave en opdaterings statement der både indsætter unikke nøgler og i samme ombæring indsætter navnene. Godtnok skal vi stadig selv sørge for at tage højde for de nøgler der ikke findes på den oprindelige ”type” tabel, da vi nu vil joine op imod denne tabel:
insert into dim_typer
select distinct bogsalg.type, typer.tekst
from bogsalg left join typer on
bogsalg.type=typer.id
go
update dim_typer set tekst = ’N/A’ where tekst is null
go
Ovenstående SQL statement vil udføre same job som den store update statement der blev produceret tidligere, og den vil samtidig være mere effektivt. Den skal heller ikke vedligeholdes som den anden skal. Derfor er den er helt klart at foretrække.
Afslutning på denne delVi har nu fået lavet en fornuftig dimensionstabel der senere hen skal implementeres på en kube. Det er utrolig vigtigt at holde styr på at der ikke optræder inkonsistens i data mellem fact tabel og dimensionstabel, da dette vil forvanske data og derved gøre dem utroværdige.
Hvad synes du om denne artikel? Giv din mening til kende ved at stemme via pilene til venstre og/eller lægge en kommentar herunder.
Del også gerne artiklen med dine Facebook venner:
Kommentarer (2)
Rigtig god artikel...
Der er godt med de mange billeder
Endnu engang sejt!
Du skal være
logget ind for at skrive en kommentar.