
9

Tags:
c#

Skrevet af
Bruger #4522
@ 29.12.2007
1. Introduktion
I denne tredje artikel om numerisk programmering i C# skal vi kigge på hvorfor udregningerne nogle gange giver et forkert resultat.
Vi skal berøre emner som de flydende tal og hvordan de adskiller sig fra de reelle tal kendt fra matematikken; derudover beskriver jeg heltallene og hvilke problemer de har. Grundlæggende handler det om hvorfor man skal passe på med ens udregninger på datamaten; samt hvordan man undgår de mest basale fejl når man udvikler software som indeholder nogle numeriske udregninger.
Denne artikel omfatter emner som er helt essentielle at forstå såfremt man producerer kode som indeholder beregninger der er mere komplicerede en blot lidt addition og multiplikation - selv noget så simpelt som at bruge formlen for rødder i andengradsligninger kan give et forkert resultat. Hvis man blot blindt kopierer formler fra ens matematikbog er man sikker på at rode sig ud i noget rigtig møg.
Vi starter med at kigge på heltallene - det er dem vi tæller på: 1, 2, 3...
2. Heltal
C# forsyner os med otter heltalstyper:
sbyte,
byte,
short,
ushort,
int,
uint,
long,
ulong. Disse typer bruges til at repræsentere heltallene kendt fra matematikken; forskellen de otte typer imellem ligger i hvilken rækkevide de har - dvs. hvor meget de dækker af heltalslinjen. Ingen af typerne dækker hele heltalslinjen da det vil kræve en datamat med en uendelig hukommelse. Og det er netop her problemet med udregninger med heltalene ligger.
For at undgå disse problemer, hjælper det at forstå at heltallene, repræsenteret af vores heltalsdatatyper, ikke ligger på en heltalslinje som i matematikken, men som tal på en urskive. Men mere om det om lidt senere.
2.1 De otte heltalstyper
Som nævnt i forrige afsnit giver C# os otte heltalstyper. Deres størrelse og rækkevidde er angivet i følgende tabel.
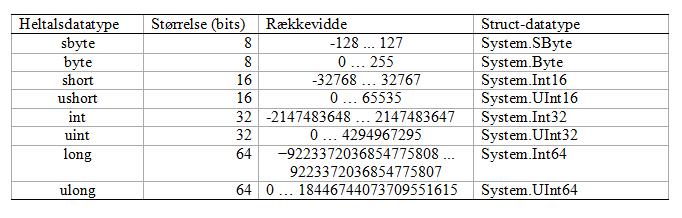
Bemærk at i C# er de indbyggede taldatatyper (både heltalsdatatyperne og de flydende tal, som vi kommer ind på senere i artiklen) faktisk blot et alias for en
struct datatype der nedarver fra
System.ValueType. For eksempel er
int et alias for
System.Int32, det betyder at man f.eks. kan bruge
new operatoren ved erklæring og initialisering af en
int:
int someInt = new int();
Diss
structs har også en min og max
property som illustreret i følgende kode:
using System;
namespace TheNumberStructs
{
public sealed class Program
{
static void Main()
{
Console.WriteLine("The range of sbyte:");
Console.WriteLine(sbyte.MinValue);
Console.WriteLine(sbyte.MaxValue);
Console.WriteLine();
Console.WriteLine("The range of byte:");
Console.WriteLine(byte.MinValue);
Console.WriteLine(byte.MaxValue);
Console.WriteLine();
Console.WriteLine("The range of short:");
Console.WriteLine(short.MinValue);
Console.WriteLine(short.MaxValue);
Console.WriteLine();
Console.WriteLine("The range of int:");
Console.WriteLine(int.MinValue);
Console.WriteLine(int.MaxValue);
Console.WriteLine();
Console.WriteLine("The range of uint:");
Console.WriteLine(uint.MinValue);
Console.WriteLine(uint.MaxValue);
Console.WriteLine();
Console.WriteLine("The range of long:");
Console.WriteLine(long.MinValue);
Console.WriteLine(long.MaxValue);
Console.WriteLine();
Console.WriteLine("The range of ulong:");
Console.WriteLine(ulong.MinValue);
Console.WriteLine(ulong.MaxValue);
Console.WriteLine();
}
}
}
Programmets output er vist i følgende billede, bemærk at det stemmer overens med ovenstående tabel.
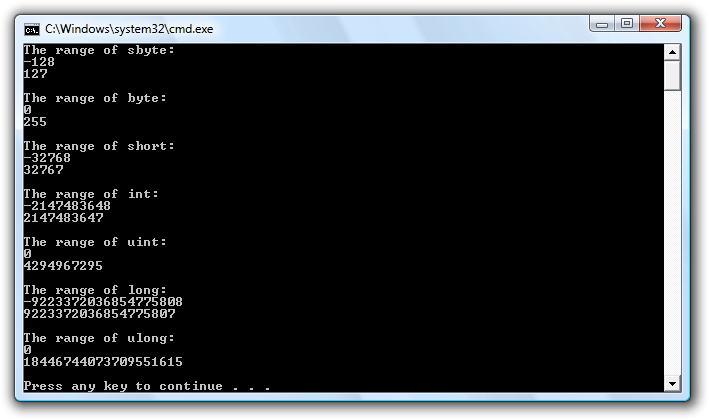
Bemærk at for de heltalsdatatypers vedkommende der har fortegn (og altså dækker både negative og positive værdier), er den absolutte værdi af datatypens minimumsværdi præcis én større end den samme datatypes maksimumsværdi. F.eks. spænder heltalsdatatypen
sbyte (
s betyder "signed") fra -128 til 127, og som nævnt er |-128| = 128 præcis én større end 127. Det betyder at halvdelen af rækkevidden er negativ og den anden halvdel dækker 0 og positive tal.
Når man i C# udfører en beregning har resultatet en datatype der er afhængig af operandernes datatyper og dette følger et sæt regler som nu vil blive forklaret.
Først skal det forstås at hvis man ikke bruger et suffix vil enhver heltals værdi, f.eks. "4", regnes som værende en
int. Det illustreres i følgende kodeeksempel:
int a = 5 * 4; // udregnes som om 5 og 4 er en int hvorfor
// resultatet også er en int
Man kan bruge et suffix for at ændre det. F.eks. vil suffixet "L" betyde at en værdi regnes for at være af datatypen
long og "M" vil betyde at en værdi regnes for at være af datatypen
decimal (
decimal er en flydende datatype, mere om den senere).
Når binære beregninger (dvs. udregninger bestående af to operander og en operator) udføres med variabler følges følgende regler, en proces vi kalder "binær numerisk avancement" (bemærk at vi nu kun betragter heltals datatyper; når vi kommer til de flydende tal vil vi støde på lignende regler og vi vil da forene begge regelsæt til et komplet sæt af avancementregler ved binær numeriske beregninger). Reglerne skal bruges i den rækkefølge de står nævnt.
- Hvis én af datatyperne er en ulong vil den anden datatype avancerer til en ulong (og resultatet bliver ligeledes ulong), medmindre den anden datatype er sbyte, short, int eller long i hvilket tilfælde vi vil få en kompileringsfejl. Problemet med de nævnte typer her er at de kan indeholde negative tal hvilket en ulong ikke kan, og da en ulong kan indeholde tal der kan være alt for store til de nævnte datatyper, findes der ingen meningsfuld konvertering typerne imellem, og vi ender med en kompileringsfejl.
- Ellers, hvis én af datatyperne er long vil den anden blive konverteret til long.
- Ellers, hvis én af datatyperne er uint og den anden er en sbyte, short eller int bliver begge operander konverteret til en long. Dette tilfælde er lidt som #1 ovenfor, bortset fra at her kan vi løse problemet ved at andvende en long.
- Ellers, hvis én af datatyperne er en uint bliver den anden operand konverteret til en uint.
- Ellers bliver begge operander konvertert til int
Som det kan ses vil vi, når vi arbejder med heltlasdatatyperne, altid udføre beregninger med mindst en
int, også selvom vi f.eks. adderer to
short.
Følgende tabel giver nogle eksempler på brug af disse regler:

C# understøtter selvfølgelig de forventede aritmetiske operatorer: *, /, %, + og -. Division med to operander der begge er en heltalstype resulterer også i et heltal - mulige tal efter kommaet smides simpelt hen væk. Med andre ord giver heltalsdivisionen 5/4 resultatet 1 og ikke 1,25. Modulusoperatoren kan bruges til at få fingrene i resten efter en heltalsdivision. F.esk. vil 5%4 give 1 da resten efter heltalsdivisionen 5/4 er 1 (= 4 * 0.25). Hvis vi har to heltal,
m og
n så gælder følgende:
(m/n)*n + (m%n) = mLad os prøve at regne dette igennem med vores 5/4-eksempel. Følgende trin viser udregningen og efter hver linje har jeg i parentes angivet hvilken del af ovenstående ligning jer har udregnet:
5/4 = 1. (m/n)
1*4 = 4. ((m/n)*n)
5%4 = 1. (m%n)
4 + 1 = 5. ((m/n)*n + (m%n))
5 = 5. ((m/n)*n + (m%n) = m)
Modulusoperatoren er ekstrem nyttig, også i mange hverdagssituationer. Skal man f.eks. undersøge om et tal er lige eller ulige kan
if(variable % 2 == 0) bruges (et lige tal vil give en rest på 0 efter en heltalsdivision med 2). Hvis man har bruge for at hive et tals højre ciffer af én efter én kan
% også bruges.
Nogle få computersprog har en eksponent operator, men den findes ikke i C#. Denne funktionalitet findes i stedet i metoden
Pow i
Mathklassen.
Lad os så snakke lidt multiplikation, for især ved multiplikation er det vigtigt at ihukomme ovenstående regler for binær numerisk avancement. Hvis vi multiplicerer to
int bliver resultatet også en
int! C# kaster ikke nogle exceptions selvom vi får overflow ved heltalsaritmetik - det er altså vores eget ansvar! Følgende eksempel illustrerer dette. Jeg initialiserer en
int med den størst mulige værdi, og udskriver den til konsollen. Derefter udskriver jeg produktet af variablen og 2.
namespace IntegerMultiplication
{
class Program
{
static void Main(string[] args)
{
int a = 2147483647;
System.Console.WriteLine(a);
System.Console.WriteLine(2*a);
}
}
}
Kørsel af programmet ses i følgende skærmbillede.
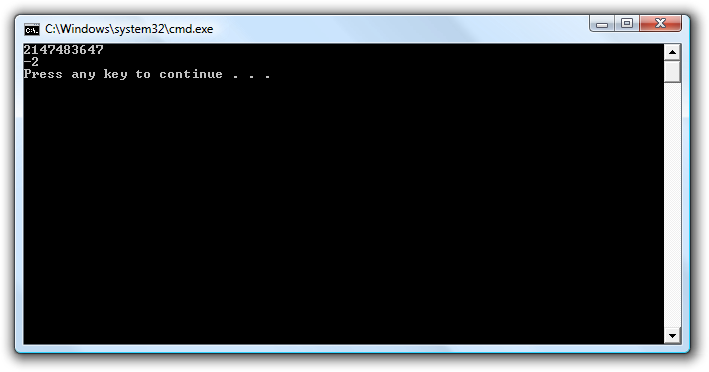
Som det ses er udregning nummer to tydeligvis noget vrøvl rent matematisk (2 * 2147483647 er ikke lig med -2), men set ud fra computerens heltalsaritmetik giver det mening. Dette er et eksempel på at når vi snakker computer-heltalsaritmetik kan vi ikke betragte heltallene som liggende på en heltalslinje men skal i stedet se dem som tal på en urskive. Det vender vi tilbage til lidt senere.
Man vil dog få smidt en exception i hovedet hvis man prøver at dividere med nul. Tag for eksempel følgende kode:
using System;
namespace DivideByZero
{
class Program
{
static void Main()
{
int a = 5;
int b = 0;
Console.WriteLine(a/b);
}
}
}
Kørsel resulterer i følgende:
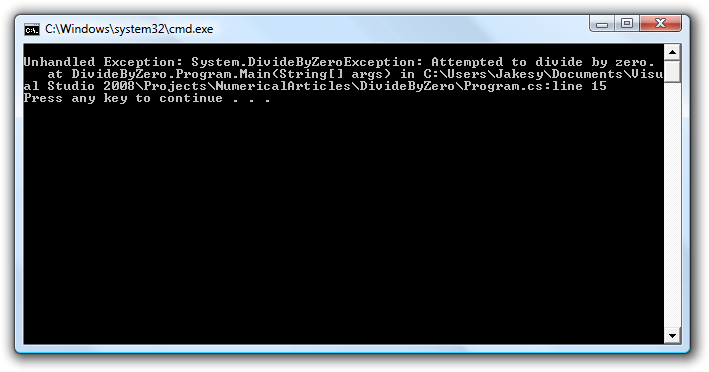
Man bliver mødt af samme exception hvis man bruger modulus operatoren (%) med nul i nævneren.
2.2 Repræsentation af heltal i computeren
Det vil være givtigt kort at diskutere hvordan computeren gemmer tal internt.
Computeren er en binær maskine, og derfor gemmes tegn og tal internt som en bit-streng (det gælder også i tilfælde med virtuelle maskiner som Java Virtual Machine og Common Language Runtime).
En bit-streng består af en række af bits, så den mindste enhed vi arbejder med er en bit.
En bit kan repræsenterer to forskellige værdier, f.eks:
- et eller nul
- Tændt eller slukket
- Rigtig eller forkert
Vi kan altså bruge én bit til at repræsentere to ting. De to ting kan være relateret til hindanden som i et binært system (et eller nul), eller det kan være to helt uafhængige objekter (blå eller laserprinter).
Ligegyldigt hvad én bit repræsenterer vil vi indikere de to muligheder med tallene 1 og 0. Så ovenstående liste bliver til:
- et (1) eller nul (0)
- Tændt (1) eller slukket (0)
- Rigtig (1) eller forkert (0)
- blå (1) eller laserprinter (0)
Når vi arbejder med bit-strenge arbejder vi altså med strenge af 1 og 0. F.eks.:
011001001001
eller
111111111111
Computerfolk har nogle forskellige udtryk/termer som de bruger om forskellige bitstrenge.
nibble: en nibble er fire bits. En nibble er interessant da den kan repræsenteres af et heksadecimalt tal (4 bits kan repræsentere 2*2*2*2 = 16 mulige objekter, og ét heksadecimalt tal kan jo netop være 1-16 eller rettere 1-F), men en computer kan ikke tilgå en nibble i hukommelsen (dertil er den for lille for nutidens maskiner til at det vil være effektivt).
byte: en byte har du helt sikkert hørt om før. En byte er otte bits. Og kan adresseres direkte på de fleste CPUer, hvorfor man i del fleste computersprog kan finde en datatype der har størrelsen én byte. I C# hedder denne datatype netop
byte (eller
sbyte hvis vi vil have den med fortegn).
Vi nummererer tit de enkelte bits i en byte med tal. Det er illustreret på følgende figur.
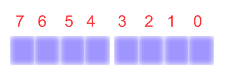
Bit nul kaldes for den mindst signifikante bit eller for "low-order bit" (også LO bit). Derimod kaldes bit 7 for den mest signifikante bit eller for "high-order bit (også HO bit).
Man kan også støde på udtrykket
word, og dets betydning er lidt forskellig afhængig af hvilket CPU man snakker om. Når vi snakker om 80x86 CPUer er en word som regel 16 bits. Følgende figur viser nummereringen af bits i en 16-bit word.

I vores word er bit 0 vores LO bit og bit 15 er vores HO bit. Vi kan også opdele vores word i to bytes, som illustreret i næste figur.
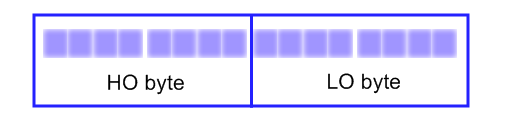
Der er også noget der hedder
double word. Jeg vil ikke illustrere den, da det nok er klart nu hvordan den ser ud. Den består selvfølgelig af to words (32-bit): en LO word og en HO word.
De fleste af vores nuværende maskiner er 32-bit maskiner, dvs. de håndterer objekter med størrelser op til 32-bit (double word) ekstremt effektivt. Større objekter som f.eks. 64 eller 128 bit håndteres derimod mindre effektivt. I skrivende stund er der ved at ske en langsom overgang til 64-bit maskiner. 64 bit er ubegribeligt meget! Overgangen fra 16 til 32-bit i 80erne og 90erne forøgede vores adresserbare lager i computeren med en faktor 65.000. Overgangen fra 32-bit til 64-bit vil derimod forøge det adresserbare lager med en faktor på fire milliarder! Det er meget. Rigtig meget. Som
Jeff Atwood skriver på hans gode blog (Coding Horror), så vil der selvfølgelig på et tidspunkt være en overgang fra 64-bit til 128-bit, men det er ikke sikkert det vil ske i vores levetid da 64-bit er enormt.
En bitstreng på to bits kan repræsentere 4 forskellige objekter, tilstande, tal, whatever. Hvis den er på 3 bits kan den repræsenterer 8 forskellige objekter, osv.
For at være helt præcis kan en bit streng bestående af
n bits repræsentere 2^n forskellige objekter.
Når en computer gemmer et heltal gemmes det som sagt som en bitstreng. Det binære talsystem er, ligesom vores decimale titalssystem, et positionssystem, hvilket betyder af et tal har forskellig værdi afhængig af hvor i en streng tallet står. I et tal fra vores titalssystem kan 1 f.eks. angive en tiere, eller et hundrede, eller et tusinde osv.
Som eksempel lad os kigge på tallet 113. Hvis vi taget et ciffer ad gangen fra højre betyder 113 i titalssystemet helt generelt (3 * 10^0) + (1 * 10^1) +(1 * 10^2) = 3 + 10 + 100 = 113. Så et tal
x betyder altså
x multipliceret med talsystemets base opløftet til en potens, hvor
xs position angiver potensen. I titalssystemet er basen ti. I vores eksempel stod tallet 3 på position 0 fra højre (vi tæller fra 0) så her betyder 3 altså 3 * 10^0 hvilket giver 3 * 1 som er lig med 3. Næste tal (fra højre af) er et 1-tal. Det står i position 1 så her betyder 1 altså 1 * 10^1 hvilket giver 10. Det sidste ettal står på position 2 så her betyder 1 altså 1 * 10^2 hvilket giver 100. Lægger vi de tre tal sammen (100, 10 og 3) får vi 113.
Det binære system fungerer på fuldstændig samme måde. Bortset fra at vi kun har to forskellige tal at arbejde med, 1 og 0, samt at basen er 2.
Lad os kigge på eksemplet 110. Det betyder faktisk (0 * 2^0) + (1 * 2^1) + (1 * 2^2) = 2 + 4 = 6. Så det binære tal 110 er i vores titalssystem 6.
Når en computer gemmer et tal uden fortegn (dvs. unsigned) gemmes tallet blot som en binær streng. Hvis vi f.eks. har en variabel af typen
byte og gemmer tallet 6 i variablen, vil variablen indeholder bitstrengen "0000 0110". Det er simpelt og ligetil.
Men hvad med negative tal? Hvad hvis vi har en variabel af typen
sbyte? Det mest simple ville nok være at bruge den mest signifikante bit som en fortegnsbit. Vi kunne f.eks. blive enige om at hvis den er 1 er tallet negativ og hvis den er 0 er tallet positivt. Med andre ord vil "0000 0110" være det samme som 6 (nøjagtig som før), mens "1000 0110" vil betyder -6 (bemærk at den mest signifikante bit er nu 1). Selvom dette system forekommer både logisk og simpelt har det visse problemer. F.esk. vil tallet 0 have to repræsentationer "0000 0000" og "1000 0000" (dvs. 0 og -0). Derudover viser det sig at dette system gør binær addition mere kompliceret end nødvendig.
I stedet benytter man et system der hedder "tos komplement". Som før benytter vi den mest signifikante bit som fortegnsbit, så positive tal er repræsenteret som før. Hvis vi så ønsker at repræsenterer et negativt tal negerer vi et tal på følgende måde.
- Inverterer alle bits i tallet. Dvs. alle 0 bliver 1 og alle 1 bliver til 0
- Læg 1 til det invertede resultat (her skal du ignoerer evt. overflow)
Lad os illustrerer dette med vores 6/-6 eksempel. I en
sbyte vil 6 være gemt som "0000 0110". Via tos komplement teknikken får vi vores negative tal:
"0000 0110" +6 i binær
"1111 1001" De otter bits er inverteret
"1111 1010" Adderet 1 og har nu resultatet: -6 i binær
Hvis vi benytter teknikken på -6 ender vi hvor vi startede med +6. Det kan du selv prøve.
2.3 Urskiven
Det jeg har prøvet at pointere omkring heltalsaritmetikken på computeren er at den adskiller sig fra matematikkens aritmetik i at den ikke er uendelig. I matematikken ligger heltallene på en uendelig heltalslinje som i følgende figur.

Vi er vant til at uanset hvilket regnestykke vi udsætter denne heltalslinje for vil der altid være et resultat, da den er uendelig. Den strækker sig så at sige fra "minus uendelig" til "positiv uendelig".
Det er på ingen måde tilfældet i C# (eller nogle andre programmeringssprog) som vi også så tidligere i et program.
Hvis vi tager den største værdi i en C# heltalsdatatype, f.eks.
int, og adderer 1 vil værdierne i datatypen ligesom bide hindanden i halen, så vi ender med det mindste tal, som i
ints tilfælde er et stort negativt tal - hvis vi have brugt en datatype der ikke havde negative tal vil vi ende op med 0. Det er det jeg mener med at man skal forestille sig at datatypernes tal ikke ligger på en heltalslinje som i matematikken, men på en urskive.
Følgende figur viser denne urskive for
bytes tilfælde hvor vi kun har positive tal.
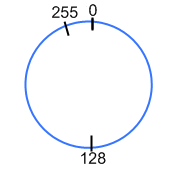
Så hvis vi på denne urskive adderer én til værdien 255 får vi 0 - et resultat som matematisk set er helt forkert, men det er konsekvensen af datatypens begrænsede rækkevidde.
Følgende C# program viser dette i praksis. Jeg erklærer og initialiserer to
bytes; den først til værdien 255 den anden til 1. Derefter erklærer og initialiserer jeg en tredje
byte til summen af de to første
bytes. Bemærk at pga. reglerne om binær numerisk avancement bliver begge
bytes i summationen forfremmet til
ints hvorfor vi bliver nød til at "caste" resultatet tilbage til en
byte (hvis vi havde gemt summationen i en
int vil vi havde fået det korrekte resultat på 256).
using System;
namespace ByteWrapAround
{
public sealed class Program
{
static void Main(string[] args)
{
byte a = 255;
byte b = 1;
byte c = (byte)(a + b);
Console.WriteLine(c);
}
}
}
Kørsel af ovenstående program giver følgende:
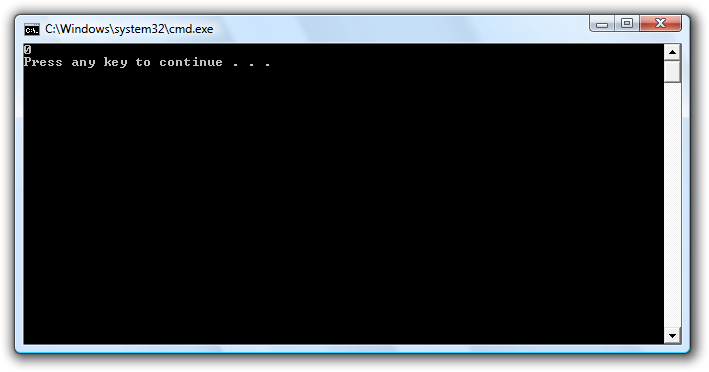
Urskiven i action! 255 + 1 er åbenbart 0, i hvert fald i computerens urskive-aritmetik. Så pas nu på. Og husk at C# kaster ingen "exceptions" pga. sådanne et "overflow".
Næste billede viser urskiven for datatypen
int.
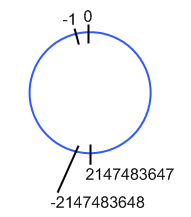
Som det ses kan addition af to store tal (af datatypen
int) resultere i en negativ sum. Sikken redelighed vi kan komme ud i hvis vi bare lukker øjnene for det!
Vigtigheden af at forstå og håndtere disse programmerings-fælder kan ikke undervurderes. Disse "urskiver" kan være totalt ødelæggende for heltalsaritmetikken. Hvorfor du skal være absolut sikker på at valget af dine datatyper er godt nok samt at du ikke udfører beregninger som kan resultere i overflows, eller at du i hvert fald er klar over det og håndterer det på den ene eller anden måde.
Følgende kodeboks viser et C# program som illustrerer
ints urskive. Jeg initialiserer en
int variabel med værdien 2147483646 som er én mindre end
ints maksimumværdi. Herefter udskrive jeg fem linjer som viser additionen af min variabel med henholdsvis 1, 2, 3, 4 og 5. Kun den første linje udskriver det korrekte resultat, de 4 efterfølgende linjer er forkerte grundet vores nu så bekendte urskive og den deraf forkerte heltalsaritmetik.
using System;
namespace IntClockface
{
public sealed class Program
{
static void Main()
{
int aNumber = 2147483646;
for (int i = 1; i < 6; ++i)
{
Console.WriteLine("2147483646 + {0} = {1}", i, aNumber + i);
}
}
}
}
Kørsel giver følgende:
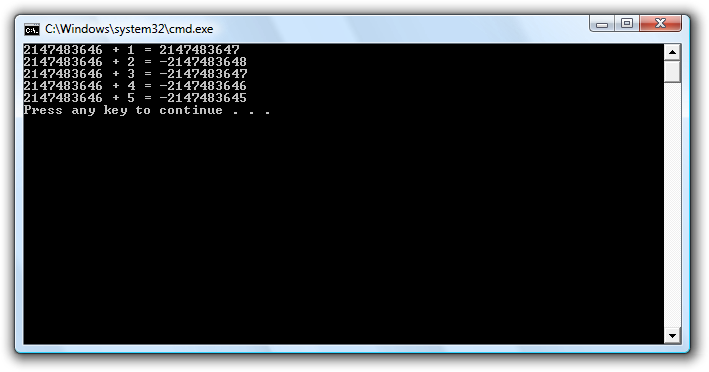
Summa summarum: Pas på med heltalsaritmetikken i dine programmer.
3. De flydende tal
Som vi lige har set besidder heltallene en del problemer, som man bestemt skal være opmærksom på når man programmerer. Men efter min personlige mening, er heltallenes problemer til at overse og til at arbejde med. De problemer der eksisterer med de flydende tal derimod, kan være lidt sværere at forstå, finde og bare generelt være rigtig drilske. Heldigvis kan man med lidt viden, og god programmeringsskik, gardere sig ganske pænt imod dem, ligesom med heltallene.
Så lad os få præsenteret denne viden. Jeg vil starte med at snakke om de faldgrupper man skal være opmærksom på når man arbejder med flydende tal.
3.1 Mål for fejl
Vi vil under vores diskussion af de flydende tal se en del fejl i vores udregninger, og det er rart at have nogle mål for disse fejl.
I numerisk analyse benyttes følgende fejlmål:
Absolut fejl: Den absolutte fejl er forskellen mellem den beregnede værdi og den korrekte værdi, altså:
absolut fejl = | beregnet værdi - korrekt værdi |
Relativ fejl: Den relative fejl er forholdet mellem den absolutte fejl og den korrekte værdi, altså:
relativ fejl: = (absolutte fejl) / (korrekt værdi)
Procentvise fejl Den procentvise fejl er den relaive fejl i procent, altså:
procentvise fejl = relative fejl * 100%
3.2 Afrunding
Heldigvis hedder de flydende tal i C# ikke
real som er tilfældet i andre programmeringssprog som f.eks. FORTRAN. En sådanne betegnelse kunne foranledig svage sjæle til at tro at en
real er det samme og ligeså kapabel som et af de reelle tal fra matematikken.
Det er dog lang fra tilfældet.
I heltallenes tilfælde talte vi om at p.g.a. computerens endelige hukommelse er det ikke muligt at repræsentere hele heltalslinjen. Det samme er selvfølgelig tilfældet for de flydende tals vedkommende. Ligesom heltallene har de en begrænset rækkevide.
Men de flydende tal er endnu mere lumske end det. For i modsætning til heltallene kan en datatype for et flydende tal ikke repræsentere alle mulige værdier i datatypens rækkevidde. Det er ikke så underligt når man tænker nærmere over det. Mellem to hvilke som helst tal på den reelle tallinje er der en uendelig mængde at tal, og det var jo ikke tilfældet på vores heltalslinje. Mellem 1 og 2 på heltallinjen er der ingen tal. Mellem 1 og 3 er der ét tal, og det er tallet 2. Men på den reelle tallinje er der mellem 1 og 2 uendeligt mange tal. 1,000001 f.eks., eller 1,99999999000100019 eller 1,000000000000000000000000000000000000000000000000001 osv. Så selvom de flydende tal så at sige "afdækker" et område af den reelle tallinje kan de rent faktisk kun repræsentere en minimal delmængde af denne rækkevidde.
Og det leder til afrundingsfejl.
I vores decimalsystem kan vi ikke repræsentere 1/3 fuldstændigt. Vi kan skrive 0.333333... hvor de tre punktummer signalerer at der følger et uendeligt antal 3-taller. Ligeså med 1/7 og mange andre brøker.
Derimod kan vi godt repræsentere 1/4 fuldstændig for 1/4 = 0,25.
Så længe nævneren i en brøk kan deles ligeligt op i et tal der er en potens af ti, kan vi udtrykke tallet fuldstændig som en decimalbrøk. 4 kan deles ligeligt op i 10^2: 100/4 = 25. Dette er ikke tilfældet med tre. Der findes ikke en potens af ti som kan deles ligeligt med tre.
Lad os med følgende program se hvordan computerens binære talsystem har det med disse brøker.
using System;
namespace Fractions
{
public sealed class Program
{
public static void Main()
{
for(int denominator = 2; denominator < 10; ++denominator)
{
Console.WriteLine("{0}/{1} (float version): {2}", 1, denominator, 1.0f / Convert.ToSingle(denominator));
Console.WriteLine("{0}/{1} (double version): {2}", 1, denominator, 1.0 / Convert.ToDouble(denominator));
}
}
}
}
Kørsel giver:
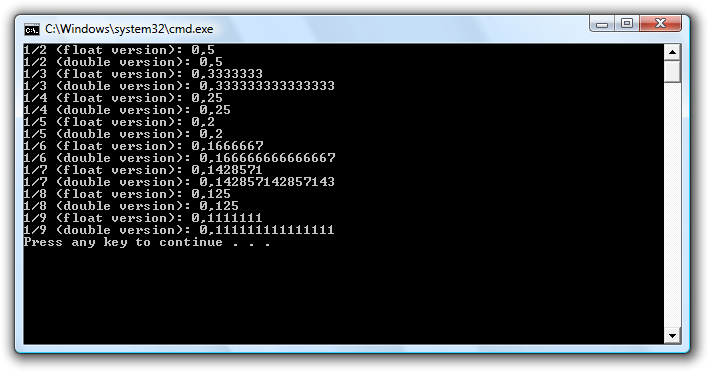
Som det ses af outputtet set brøkerne egentlig ok ud. Der er ingen problemer med 1/2, 1/4, 1/5 og 1/8. 1/3 ser fin nok ud taget i betragtning af vi kun har en endelig mængde af 3-taller til rådighed. 1/6 bliver afrundet så et 6-tal rundes op til et 7-tal. 1/7 bliver også afrundet i
double versionen og 1/9 har kun endelig mængde et-taller til rådighed.
Disse manglende ciffer hos 1/3, 1/6, 1/7 og 1/9 giver problemer som vi skal se med følgende program. I dette program summerer vi nogle af brøkerne rigtig mange gange og ser om vi får hvad vi forventer. Programmer er som følger:
using System;
using System.Globalization;
namespace FloatingPointSummation
{
public sealed class Program
{
public static void Main()
{
for (int denominator = 2; denominator < 6; ++denominator)
{
float a = 0.0f;
for(int i = 0; i < 1680; ++i)
{
a += 1.0f/Convert.ToSingle(denominator);
}
Console.WriteLine("{0} summed 1680 times are: {1}, and should have been {2}",
string.Format("1/{0}", denominator, CultureInfo.CurrentCulture), a, 1680/denominator);
Console.WriteLine();
a = 0.0f;
}
}
}
}
Resultatet af at køre programmer er:
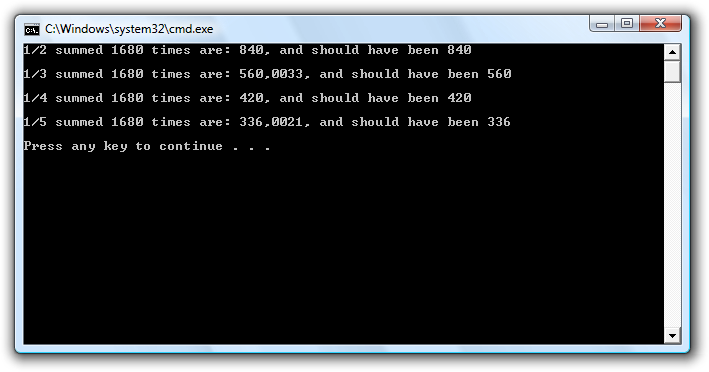
Som det ses får vi en betydelig fejl ved summation af 1/3. Computeren kan tilsyneladende ikke repræsentere 1/3 godt nok, og denne akkumulering af mange små fejl er synligt i resultatet. Det samme med 1/5, som ellers i forrige program så ud til at være godt nok repræsenteret i maskinen. Men tilsyneladende er der en lille gemt fejl som så bliver akkumuleret for hver summation og vi ender med det fejlagtige resultat. Det er dog ikke overraksende af 1/2 og 1/4 klarer sig rigtig godt da de begge er direkte potenser af 2.
3.3 Hvordan man kan lave en stor fejl på få linjer: "Cancellation" fejl
Vi skal nu se hvordan man meget hurtigt kan ende med en stor fejl på få linjer - uden brug af løkker eller lignende. Vi vil også udregne nogle fejlmål fejlene.
Idéen er som følger.
Lad os sige at vi har lavet en beregning hvor resultatet skulle have været 1/4, men vi ente op med tallet 10.000.002/40.000.0000 i stedet. Hvad er fejlmålene på det? Følgende program udregner absolutte og procentvise fejl på det. Umiddelbart kan vi dog godt se at den absolutte fejl er 2/40.000.000, en ganske lille fejl.
Hvis vi nu tager den inverse af den absolutte fejl skulle vi gerne få 20.000.000 - er det tilfældet? Det vil vi også udregne i følgende program. Jeg kan afsløre at det ikke er tilfældet, hvorfor vi også udregner nogle fejlmål for det.
using System;
namespace CancellationError
{
public sealed class Program
{
public static void Main()
{
float a = 1.0f/4.0f;
float b = 10000002.0f/40000000.0f;
float absolutError = Math.Abs(a - b);
float percentageError = absolutError/b*100;
Console.WriteLine("We wanted {0}", a);
Console.WriteLine("But got {0}", b);
Console.WriteLine("The absolute error is thusly: {0}", absolutError);
Console.WriteLine("The percentage errror is: {0}%", percentageError);
Console.WriteLine();
Console.WriteLine("Now we'll invert the absolutte error...");
Console.WriteLine("We wanted {0}", 20000000.0f);
Console.WriteLine("But we got {0}!!!!", 1.0f/absolutError);
Console.WriteLine("The absolute error of this is: {0}", Math.Abs(1.0f / absolutError - 20000000.0f));
Console.WriteLine("And the percentage error is very high: {0}%", Math.Abs(1.0f / absolutError - 20000000.0f)/20000000.0f*100);
}
}
}
Kørsel giver:
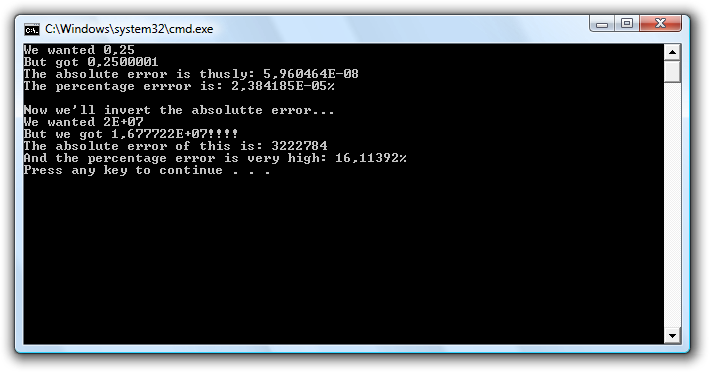
Første sæt af udregninger giver en lille fejl. Dog er den absolutte fejl ikke korrekt. Den burde have været 0,00000005 (5x10^-8), men er tætter på 6x10^-8. Men ok., det er dog kun en lille afrundingsfejl.
Men se nu hvad der sker.
Nu tager vi den inverse af den absolutte fejl (som har den lille netop diskuterede afrundingsfejl), og så eksploderer det, og vi ender med en fejlprocent på godt 16!.
Det der er på spil er det der på engelsk hedder en "cancellation"-fejl. Fejlen opstår fordi vi subtraherer to meget tætte tal (1/4 og 10000002/40000000) hvor der er en afrundingsfejl på det ene. Resultatet er et tal hvor alle de rigtige signifikante cifre er væk og vi har de forkerte tilbage.
Med andre ord skal man passe på med at arbejde videre med resultatet af en subtraktion af to meget ens tal da et af (eller begge) af tallene kan (og tit vil) have en afrundingsfejl, hvilket betyder af resultatet af subtraktionen som oftest kun vil består af de forkerte cifre da alle de signifikante rigtige cifre forsvandt ved subtraktionen.
Lad os nu benytte vores nye viden og se hvordan vi kan gardere os imod en "cancellation"-fejl når vi skal bruge formlen for rødder i et anden grads polynomium (ax^2 + bx + c) hvor a != 0. Formlen kender du helt sikkert fra gymnasiet:
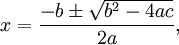
Hvis nu
b er positiv og
4ac er meget lille relativt til
b, vil (-b + sqrt(b^2 - 4ac)) resultere i en "cancellation"-fejl. Her kan vi så i stedet benytte (-b - sqrt(b^2 - 4ac)), som der ikke er problemer med, som tælleren i brøken til at finde den ene rod, og så benytte at
x_1*x_2 = c/a (her er x_1 og x_2 de to rødder), til at finde den anden rod.
Såfremt
b er negative er situationen omvendt; her vil (-b - sqrt(b^2 - 4ac)) give en "cancellation"-fejl og vi benytter så (-b + sqrt(b^2 - 4ac)) i stedet.
3.4 Mere om afrundingsfejl
Som tydeliggjort er afrundingsproblemet årsager til mange fejl i udregninger med flydende tal.
Disse afrundingsfejl opstår fordi at vi, ligesom med heltallene, ikke kan repræsentere alle tallene i computeren. I matematikken er den reelle tallinje uendelig hvilket ikke lader sig repræsentere i en computers endelige hukommelse. Så vi må nøjes med nogle få tal. Det er vigtigt at forstå at den reelle tallinje, i modtsætning til heltalslinjen, er kontinuerlig, hvilket vil sige at mellem hvilke som helst to reelle tal er der et uendeligt antal andre reelle tal. Derudover har et reelt tal i matematikken en uendelig præcision.
Det er ikke tilfældet med flydende tal i C#. Her har vi ikke bare et mindste og største tal, men også en endelig præcision.
I C# har vi to datatyper til de flydende tal:
float og
double. Følgende angiver deres rækkevidde og præcision:
float; rækkevidde: ±1.5e-45 til ±3.4e38; præcision: 7 cifre
double; rækkevidde: ±5.0e-324 to ±1.7e308; præcision: 15-16 cifre
Her skal jeg henlede din opmærksomhed på to ting: rækkevidden er approksimativ og i
doubles tilfælde kan præcisionen svinge mellem 15 og 16 cifre. Dette kan umiddelbart synes lidt bisart, men det skyldes at det her er angivet i deicmal-systemet hvorimod computeren rent faktisk, som vi jo har snakket om, repræsenterer der i det binære talsystem.
Derudover har C# endnu en datatype som er velegnet til finansielle/økonomiske udregninger. Den hedder
decimal og har følgende rækkevide og præcision:
decimal; rækkevidde: ±1.0 × 10-28 to ±7.9 × 1028; præcision: 28-29 cifre
Denne datatype har en mindre rækkevidde sammenlignet med
float og
double, men til gengæld har den en meget større præcision.
Ikke blot har vi som nævnt et største og mindste tal, men der er også huller i tallinjen (grundet vores endelige præcision).
Internt gemmes et flydende tal i to dele: en signifikant og en eksponent. Du kender højst sandsynligt disse to dele fra den eksponentielle skrivemåde. Tallet 0,003456 gemmes som: 3,456 (= signifikanten) og -3 (= eksponenten), ligesom i den eksponentielle skrivemåde: 3,456*10^-3. Signifikanten har
altid et enkelt ciffer (ikke nul) til venstre for decimalkommaet (undtagelsen er for tallet nul).
Umiddelbart ville vi nok forvente at de mulige tal vi kan repræsentere er ligeligt fordelt over vores mulige rækkevidde. Dette er illustreret i følgende figur.

I ovenstående figur ses en tallinje som symboliserer den relle tallinje. De blå cirkler repræsenterer de tal vi kan repræsentere i en imaginær datatype for flydende tal. Som forventet er de tal vi har til rådighed ligeligt fordelt over vores datatypes rækkevidde - eller sagt på en anden måde: der er lige stor afstand mellem de blå cirkler.
Det er dog ikke tilfælde med flydende tal i computeren! De er i stedet meget ujævnt fordelt, med en klar forkærlighed for lavere tal. Det kunne f.eks. se sådanne ud:

Som illustreret i ovenstående figur er fordelingen af de tal vi kan repræsentere med de flydende tal meget ujævn. De datatyper vi arbejder med har selvfølgelige en pæn stor præcision så vi skal pænt langt "ud på decimalerne" for at blive fanget af det, men det er bestemt noget man skal være opmærksom på. Denne ulige fordeling skyldes den måde hvorpå vi gemmer og håndterer de flydende tal i dets to dele (signifikanten og eksponenten).
Lad os opsumere de dårlige nyheder: ikke blot har vi en begrænset rækkevide, og indenfor denne rækkevidde kan vi kun repræsentere en endelige (og meget lille) del af de rent faktiske tal der findes, men oven i det er vores tal ujævnt fordelt på vores rækkevidde.
3.5 Pas på de matematiske love!
Hvis du troede at jeg var færdig med at vise dig alle skavankerne ved de flydende tal - så må du tro om!
Nu skal vi nemlig kigge på nogle matematiske love. Nogle love som vi alle kender og holder af, og som vi går ud fra altid holder. Altid. Du kan nok godt regne ud hvor jeg vil hen med dette. Det er rigtigt - du kan ikke regne med disse love når du bruger flydende tal!
Vi kender alle den associative lov for addition:
(a + b) + c = a + (b + c)og den associative lov for multiplikation:
(ab)c = a(bc).
Derudover kender vi også den distributive lov:
a(b + c) = ab + ac.
Du har nok også hørt om følgende:
Hvis ac = bc, og c != 0, så er a = b.
Endelig kender du nok også:
Hvis a != 0, da er a(1/a) = (1/a)a = 1.
Ronald Mak har i sin bog (se Referencer nedenfor), vist at disse fem love/sætninger ikke altid gælder for flydende tal! Ja du læste rigtigt! Du kan ikke gå ud fra at de holder, og burde altså på ingen måde producere kode der er afhængig af deres gyldighed.
Dog, overholdes de kommutative love:
a + b = b + aog
ab = ba.
3.5 Binær Numerisk Avancement, Take Two
Jeg har allerede gennemgået reglerne for binær numerisk avancement for heltallenes tilfælde.
Følgende tre "regler" gælder for de flydende tal:
- Hvis én af operanderne er af typen decimal vil den anden operand blive konverteret til decimal. Hvis den anden operand er af typerne float eller double fås i stedet en kompileringsfejl.
- Ellers, hvis én af operanderne er af typen double konverteres den anden til en double.
- Elelrs, hvis én af operanderne er af typen float konverteres den anden til en float.
Vi kan forene disse med reglerne beskrevet under heltallene og herved få et regelsæt der gælder for alle tal i C#:
- Hvis én af operanderne er af typen decimal vil den anden operand blive konverteret til decimal. Hvis den anden operand er af typerne float eller double fås i stedet en kompileringsfejl.
- Ellers, hvis én af operanderne er af typen double konverteres den anden til en double.
- Ellers, hvis én af operanderne er af typen float konverteres den anden til en float.
- Ellers, hvis én af datatyperne er en ulong vil den anden datatype avancerer til en ulong (og resultatet bliver ligeledes ulong), medmindre den anden datatype er sbyte, short, int eller long i hvilket tilfælde vi vil få en kompileringsfejl. Problemet med de nævnte typer her er at de kan indeholde negative tal hvilket en ulong ikke kan, og da en ulong kan indeholde tal der kan være alt for store til de nævnte datatyper, findes der ingen meningsfuld konvertering typerne imellem, og vi ender med en kompileringsfejl.
- Ellers, hvis én af datatyperne er long vil den anden blive konverteret til long.
- Ellers, hvis én af datatyperne er uint og den anden er en sbyte, short eller int bliver begge operander konverteret til en long. Dette tilfælde er lidt som #1 ovenfor, bortset fra at her kan vi løse problemet ved at andvende en long.
- Ellers, hvis én af datatyperne er en uint bliver den anden operand konverteret til en uint.
- Ellers bliver begge operander konvertert til int
Husk at reglerne skal følges i den angivne rækkefølge!
Afslutning
Jeg har i denne artikel gjort dig, læseren, opmærksom på nogle af de faldgrupper der er ved udregninger med både heltal og flydende tal i C#. Jeg håber at der har været informativ og at du er blevet overbevist om at du skal nøje have styr på dine udregninger.
Jeg havde oprindeligt planlagt at inkludere en gennemgang af den standard som implementeringen af de flydende tal i C# (og de fleste andre programmeringssprog) bygger: IEE 754, men det blev tydeligt at artiklen vil blive for lang hvorfor jeg har gemt det emne til en anden artikel.
Referencer
Gode reference, som jeg også har konsulteret under udarbejdelsen af denne artikel, er Ronald Mak: "Java™ Number Cruncher: The Java Programmer's Guide to Numerical Computing", Chapras og Canales "Numerical Methods for Engineers", samt Randal Hyde: "Write Great Code - Understanding the Machine, Volume I".
Hvad synes du om denne artikel? Giv din mening til kende ved at stemme via pilene til venstre og/eller lægge en kommentar herunder.
Del også gerne artiklen med dine Facebook venner:
Kommentarer (6)
Igen en interessant artikel. Dog forstår jeg ikke følgende:
0000 0110 er lig 6 i titalssystemet
1111 1001 er lig -6 i titalssystemet
Hvad så, hvis man vil repræsentere tallet 249 med binære tal?
Det må jo også være 1111 1001 lige som -6. Ved computeren så, at de 8 bit er lagret som en signed byte eller hvordan fungerer det?
På forhånd tak. 5 her fra
")
Hej Michael.
Tallet 249 kan ikke gemmes i en sbyte. sbyte går kun fra -128 til 127, netop fordi vi bruger HO-bitten som fortegnsbit.
Du kan tilgengæld gemme 249 i en byte. I en byte er der ingen fortegnsbit så i en byte vil "1111 1001" være 249.
Og tak for din stemme

Et bitmønster betyder jo egentlig ikke andet end den fortolkning du ligger hen over dem, og den fortolkning bestemmer du i programmeringssproget ved vælge typen f.eks. at vælge typen int eller uint.
btw.
0000 0110 giver ganske vidst 6 uanset fortolkning, men der er flere måder og fortolke en signed int på:
en umiddelbar måde er at bruge mest betydende bit som fortegn, -6 vil da blive 1000 0110,
1111 1001 er -6 i komplement fortolkningen.
begge disse fortolkninger har den ulempe at 0 er tvetydig: f.eks. 0000 0000 eller 1000 0000 for første fortolkning, og 0000 0000 eller 1111 1111 for anden fortolkning.
Derfor bruger vi idag en fortolkning der hedder to komplement fortolkningen, og som også er den Jacob har beskrevet, i den fortolkning bliver 1111 1001 -7 og ikke -6.
To komplement systemet har så den ulempe at der ikke er lige mange lige og ulige tal, der er faktisk et ulige tal mere end lige, og det kan man så overveje hvilken betydning har for abs funktionen...
Hej Troels,
Ja, abs(-32768) returnerer vel inputtet (altså -32768).
Jeg er ikke sikker, men jeg tror C# kaster en exception hvis man prøver at negerer minimumsværdien af et tos komplement tal.
En supergod artikel! Jeg tror aldrig, jeg har lært så meget om C# fra en artikel før, og en del af det vidste jeg godt i forvejen. Nogle gange virker det som om du har siddet lidt i dine egne tanker når du har formuleret en sætning, for visse sætninger giver simpelthen bare ikke mening, men det sker også for mig, så du får stadig 5. Nu mangler jeg bare lige at finde ud af, hvordan man stemmer
")
Nå ja, vi bruger jo karmasystemet nu...
Du skal være
logget ind for at skrive en kommentar.