
17

Tags:
databaser

Skrevet af
Bruger #2730
@ 31.05.2003
Denne artikel vil gennemgå hvad der menes med normalformer i database sammenhæng. En normalform kan ses som en måde at forædle sine data på, det vil sige gøre dem bedre. Der findes fem normaliseringsformer, hvoraf vi kun vil beskæftige os med de tre første. Dette skyldes at man utrolig sjældent kommer op og bruger fjerde og femte normalform. Normalformernes formål er at lave så godt et database design som overhovedet muligt, samt "ensrette" måden man udvikler en database på. Ved at have en normaliseret database sikrer man samtidig at der ikke er redundante data i tabellerne, hvilket ville resultere i et forkert datagrundlag. Man sikrer også at databasen bliver overskuelig og nem at arbejde med. Hvis man ser på en komplet denormaliseret database vil alle data groft sagt være at finde i een tabel. Dette er ikke et særligt godt database design da der for det første findes mange dubletter (redundans) i dataene, og samtidig med at denormaliseret datastruktur er tung at arbejde med, hvis man senerer hen vil bruge sine data til præsentation eller analyse. Nedenstående er et eksempel på en denormaliseret datastruktur:
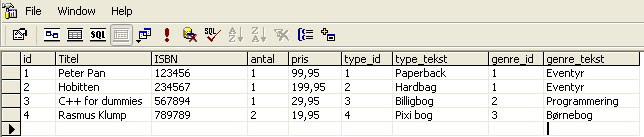
Som det fremgår tydeligt på ovenstående billede er dette en komplet denormaliseret tabel. Jeg har med vilje brugt et eksempel fra tidligere artikler da de er nemme at forholde sig til. Som det ses findes både type id samt type teksten på selve tabellen med vores facts. Dette er ikke særlig godt database design.
Første normalformJeg vil fra nu af i artiklen bruge nogle andre eksempler, de stammer alle fra nogle eksempler jeg har lavet for et par år siden da jeg læste datamatiker. Første normalform fjerner forekomster med flere attributter. Der må kun være een værdi af en given dimension pr. tuple. De eneste dimensionsværdier en tuple må have skal være atomare, eller udelelige. Dette er en gylden regel som ikke må fraviges hvis man vil opnå første normalform. Nedenstående viser et eksempel på hvordan en tabel for en afdeling kan være sammensat.

I ovenstående figur ser vi at afdelingsnummer er primær nøglen for denne tabel. Det vil sige at den unikt identificerer en forekomst på denne tabel. Pilene viser at gennem denne nøgle kan man få fat i alle de andre værdier i denne tabel. Hvis vi nu fylder noget denormaliseret data i denne tabel, og bagefter ser om vi kan normalisere det til første normalform.

I ovenstående tabel består vores redundans i at der er flere byer tilknyttet vores udviklingsafdeling. Dette er noget vi som database designere skal luge væk og formå at tage denne database til et højere niveau og forædle dataene i den. Der er i princippet tre måder vi kan gøre det på. Den første er at lave tre kolonner der hedder placering og så skrive bynavnene i disse kolonner. Dette har dog den ulempe at vi skal vide på forhånd hvor mange byer en afdeling kan befinde sig i.

Som det tydeligt kan ses på ovenstående figur har denne metode den ulempe at den placerer <NULL> værdier (NULL=tom) i de felter hvor der ikke er flere byer for en enkelt afdeling. Dette er vi heller ikke så interesseret i da det kort og godt er spild af plads, at have alle disse tomme pladser. Desuden kan vi sikkert aldrig være sikker på at en afdeling kun kan eksistere i tre byer (hvad gør man så når man i virksomheden finder ud af at det hele skal samles i een by, eller at lige pludselig er det muligt for en afdeling at eksistere i 6 forskellige byer). Derfor er denne løsning ikke altid den rigtige. Den anden løsning man kan lave, er en række for hver af de forekomster der findes i placering.
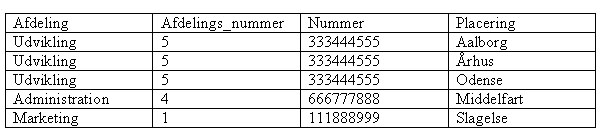
Ulempen ved ovenstående metode at løse første normalform på er at den laver redundans i vores data. Det er egentligt heller ikke så godt et design af vores database. Tredje måde at løse første normalform på er i de fleste situationer den bedste. Den består i al sin enkelhed på at lave en ny tabel der indeholder alle de unikke værdier en placering kan indeholde sammen med den tilhørende primærnøgle. Det vil sige at vi nu vil få en tabel der indeholder nogle værdier der beskriver vores facts, det er også dem vi kalder dimensionstabeller.
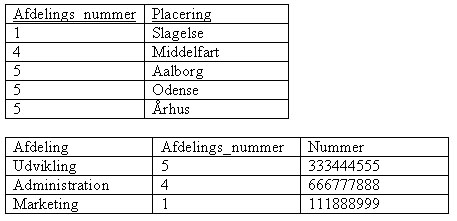
Denne metode til at opløse en denormaliseret database til første normalform er i mange situationer den bedste, da der ikke findes redundans (at der er flere værdier i dimensionstabellen med samme navn, men med forskellig nøgle er ikke redundans, de er forskellige på grund af nøglen). Det vi reelt har gjort er at opløse en tabel der ikke opfylder første normalform til to tabeller der hver i sær opfylder første normalform.For som vi definerede i starten er første normalform: "Første normalform fjerner forekomster med flere attributter. Der må kun være een værdi af en given dimension pr. tuple. De eneste dimensionsværdier en tuple må have skal være atomare, eller udelelige.". Og det er lige hvad vi har opnået.
Anden normalformAnden normalform (2NF) bygger på reglen om fuld funktionel afhængighed. Det betyder at dimensionerne evalueres op imod nøglerne og normaliseringen foretages. Hvis der kun findes en enkelt primær nøgle er tabellen allerede i 2NF. Hvis der derimod er en sammensat primær nøgle på tabellen kan den bringes til 2NF. Måden at gøre det på er ved at se hvilke dimensioner på tabellen der er 100% afhængig af den sammensatte primærnøgle. Kolonnenavnene i nedenstående skema er følgende:
CPR: CPR nummer
PNUMMER: Projekt nummer
TIMER: Antal timer på projekt
ANAVN: Den ansattes navn
PNAVN: Projekt Navn
PPLACERING: Projekt placering

Som det ses er den eneste kolonne der er afhængig af begge attributter i den sammensatte primærnøgle kolonnen TIMER (pilen der peger på TIMER, har en streg ind til to forskellige nøgler). De tre andre kan i princippet splittes ud i tre separate tabeller med hver deres enkelte primærnøgle. Dette er en måde at løse det på.
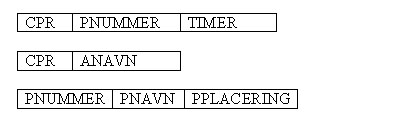
Dette er den ene måde at løse ovenstående problem på. En anden måde er at denormalisere projekt tabellen ind i employee tabellen ved at gøre nedenstående. Det er ikke så kønt med det er en mulighed og den er fuld lovlig.

Ud af de to metoder jeg har vist til at opnå anden normalform foretrækker jeg den første hvor man laver separate tabeller.
Tredje NormalformTredje normalform (3NF) bygger igen videre på 2NF, hvor man nu fjerner dimensioner, der ikke har en direkte tilknytning til primærnøglen på tabellen. Det vil sige at i den figur fra tidligere vil vi fjerne ANAVN, da den ikke har nogen tilknytning til primærnøglen som i dette tilfælde er CPR (ovenstående billede).

Tredje normalform er tilstrækkeligt når der laves kuber oven på den relationelle database efterfølgende, som det nogle gange er ønskeligt i et analysemiljø på eksempelvis Microsofts SQL Server 2000.
Hvad synes du om denne artikel? Giv din mening til kende ved at stemme via pilene til venstre og/eller lægge en kommentar herunder.
Del også gerne artiklen med dine Facebook venner:
Kommentarer (4)
Synes lige at du tøffede lidt hurtigt over 3. normalform... Trods alt den vi skal opnår.
Totalt fed artikel og MEGET teoretisk korrekt. Mange af de ting du nævner, gør jeg efterhånden automatisk allerede før jeg konstruerer databasen. Jeg tror dog, der er rigtig mange, der ville finde det nyttigt at vide disse ting. Jeg er enig med Jimmi i, at du var LIDT hurtig med 3NF.. det har nok noget med tid at gøre :-)
god artikel
Ja en god gennemgang, men synes også du kommer lidt hurtigt hen over 3. NF.
Jeg har selv skrevet lidt om emnet og de 3 foørste normalformer: <a href="http://www.designcreative.dk/blog/database_normalisering/normalisering_database_sql_foerste_normalform.htm">Normalisering af databaser</a>.
Håber linket kan bruges til lidt suplerende information, eller i hvert fald en vinkel på emnet
")
Du skal være
logget ind for at skrive en kommentar.