
11

Tags:
c#

Skrevet af
Bruger #4522
@ 20.12.2008
Hvorfor?
Før vi begynder at kigge på noget C# kode, er der et spørgsmål der trænger sig på. Hvorfor overhovedet bruge træer? C#s collection-bibliotek indeholder mange forskellige datastrukturer som lister, stakker, køer, hashsæt og "ordbøger" (dictionaries). Så er træer egentlig nødvendige? Er .NET Frameworket ikke nok?
I de fleste tilfælde: Jo. For de fleste programmeringsopgaver behøver du ikke træer; men der er nogle opgaver hvor et træ er den naturlig løsning. Hvis du f.eks. skal manipulere hierarkisk data, eller skal holde data på en måde så det bliver hurtigt at gennemsøge, er træer det oplagte valg. Derudover er træer en klassisk datastruktur i datalogi som enhver programmør bør have bekendtskab med.
Et klassisk eksempel på brugen af et træ er et såkaldt udtrykstræ som bruges til holde og evaluere et udtryk, f.eks. et C# udtryk. Tag for eksempel udtrykket "a = b + (c + 1) * 4;". Dette udtryk kan nemt repræsenteres og evalueres ved at bruge et træ. Se følgende illustration.
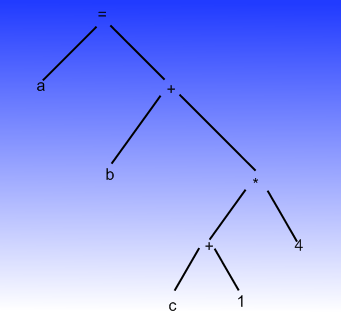
I ovenstående illustration er udtrykket opskrevet som et udtrykstræ. Udtrykket kan så evalueres ved at starte nedefra.
C# implementationen
Nu skal vi til at kigge på noget kode.
[Note: Denne del af artiklen er skrevet mens koden blev udviklet, og indeholder altså nogle af de tanker som jeg gjorde mig i løbet af denne proces. Derfor nævner jeg nogle af de ideer jeg fik undervejs, hvoraf nogle ikke blev til noget overhovedet, og andre endte med at blive virkeliggjort i koden.]
Min første idé er at lave et interface for et træ. Der findes forskellige typer af binære træer i datalogi (det vi har kigget på indtil nu er et standard binært træ), og tanken er at man kan bruge dette interface til at navigere rundt i forskellige typer af binære træer. En anden vigtig ting er navigationen rundt i træet. Da det er en datastruktur vi arbejder med vil det være naturligt at bruge den form for navigation som er indbygget i .NET frameworket. Her tænker jeg på at vi f.eks. kunne implementere IEnumerable interfacet, eller måske bare bruge iterators der så ordner det hele bag kulisserne. På den anden side er navigationen af et træ helt anderledes, end det er tilfældet ved en standard lineær datastruktur, så det kan være at det slet ikke passer til vores tilfælde. Lad os se hvad vi ender med, men nu er vi i hvert fald opmærksom på det. Under alle omstændigheder skal vi kunne navigere rundt i træet med en slags markør.
Derudover ønsker jeg at gøre træet generisk.
Mit forslag til et interface er:
- //-----------------------------------------------------------------------
- // <copyright file="BinaryTree.cs" company="Jacob Rohde">
- // Copyright Jacob Rohde. All rights reserved.
- // </copyright>
- //-----------------------------------------------------------------------
- namespace Trees
- {
- using System.Collections.Generic;
-
- /// <summary>
- /// Interface for a binary tree.
- /// </summary>
- /// <typeparam name="T">The type of objecs the tree holds</typeparam>
- public interface IBinaryTree<T> : IEnumerable<T>
- {
- /// <summary>
- /// Gets a value indicating whether the cursor is at a valid node.
- /// </summary>
- /// <returns></returns>
- bool IsValid
- {
- get;
- }
-
- /// <summary>
- /// Gets or sets the value held at the node pointed to by the cursor.
- /// </summary>
- T Value
- {
- get; set;
- }
-
- /// <summary>
- /// Gets a value indicating whether the cursor has a left child.
- /// </summary>
- /// <returns></returns>
- bool HasLeftChild
- {
- get;
- }
-
- /// <summary>
- /// Gets a value indicating whether the cursor has a right child.
- /// </summary>
- /// <returns></returns>
- bool HasRightChild
- {
- get;
- }
-
- /// <summary>
- /// Gets a value indicating whether the cursor has a parent.
- /// </summary>
- /// <returns></returns>
- bool HasParent
- {
- get;
- }
-
- /// <summary>
- /// Gets a value indicating whether the node pointed to by the cursor has a parent and is a left child.
- /// </summary>
- /// <returns></returns>
- bool IsLeftChild
- {
- get;
- }
-
- /// <summary>
- /// Gets a value indicating whether the node pointed to by the cursor has a parent and is a right child.
- /// </summary>
- /// <returns></returns>
- bool IsRightChild
- {
- get;
- }
-
- /// <summary>
- /// Gets a value indicating whether the tree is empty.
- /// </summary>
- /// <returns></returns>
- bool IsEmpty
- {
- get;
- }
-
- /// <summary>
- /// Gets the number of nodes in the tree.
- /// </summary>
- int Size
- {
- get;
- }
-
- /// <summary>
- /// Moves cursor to the left child of the cursor, or off the tree.
- /// </summary>
- void MoveLeft();
-
- /// <summary>
- /// Moves cursor to the right child of the cursor, or off the tree.
- /// </summary>
- void MoveRight();
-
- /// <summary>
- /// Moves the cursor up to the parent.
- /// </summary>
- void MoveUp();
-
- /// <summary>
- /// Inserts a new node into the tree holding the given value. If the tree is empty, the value is inserted at the root node, otherwise a node is
- /// inserted where the cursor last moved off the tree.
- /// </summary>
- /// <param name="value">The value to be hold in the new node.</param>
- void Insert(T value);
-
- /// <summary>
- /// Removes a leaf node from the tree. The cursor must be at a leaf node. The leaf is removed and the cursor moves
- /// to the parent (if any).
- /// </summary>
- /// <returns>The value that was held by the removed node.</returns>
- T Remove();
-
- /// <summary>
- /// Removes all nodes from the tree.
- /// </summary>
- void Clear();
-
- /// <summary>
- /// Moves the cursor to the root node.
- /// </summary>
- void Reset();
- }
- }
Det er altid en smagssag hvad der skal være en metode og hvad der skal være en property. Der er dog nogle grundregler. For eksempel skal man være opmærksom på at get-properties udføres på uforudsigelige tidspunkter (f.eks. ved debugging), hvorfor de som grundregel ikke må være skyld i store såkaldte "side-effects". Derudover skal en property ikke være beregningsmæssig krævende.
Jeg har valgt at implementere IEnumerable<T> interfacet. Jeg vil til at starte med se om det kan implementeres med en simpel iterator, hvis det ikke er muligt vil jeg lave min egen IEnumerator<T> implementation.
Når et
BinaryTree<T>-objekt oprettes er det tomt - uden nogle knuder. En knude indsættes i træet ved at kalde metoden
Insert. Ved at bruge
IsValid kan en bruger tjekke om markøren peger på en gyldig knude; såfremt det er tilfældet kan knudens data (værdi) hentes og sættes med
Value-egenskaben.
Navigation rundt i træet sker ved at kalde
MoveLeft,
MoveRight og
MoveUp. For at starte forfra, dvs. for at placere markøren ved roden, kaldes
Reset-metoden.
Repræsentation af elementerne
I implementationen af vores binære træ, er ideen at have en reference til dens rod. Herfra har vi så adgang til dens data og dens relaterede elementer (børn og forældre [som i rodets tilfælde vil være tom]). Generelt repræsenterer vi et undertræ som en reference til dens rod, hvorfra vi så kan få fat i dens data og andre elementer.
Vi har derfor også brug for en klasse der kan bruges til at repræsentere et binært element. Umiddelbart vil jeg tro at sådanne en element-klasse kan bruges i de forskellige repræsentationer man lave af binære træer, og jeg tror ikke at et interface vil være nødvendigt her. Så vi kan "nøjes" med at lave en generisk klasse kaldet
BinaryTreeNode<T>. Her kommer koden, og bagefter går jeg den igennem.
- //-----------------------------------------------------------------------
- // <copyright file="BinaryTreeNode.cs" company="Jacob Rohde">
- // Copyright Jacob Rohde. All rights reserved.
- // </copyright>
- //-----------------------------------------------------------------------
- namespace Trees
- {
- using System.Collections.Generic;
-
- /// <summary>
- /// Represents a node in a binary tree. The class is generic. A node is used for holding data in a binary tree. The node has references to its
- /// parent, and its left and right child. Some or all of these might be null, depending on the tree topology.
- /// </summary>
- /// <typeparam name="T">The type of the object the node holds.</typeparam>
- public class BinaryTreeNode<T> : IEnumerable<T>
- {
- /// <summary>
- /// Reference to the left child of the node.
- /// </summary>
- private BinaryTreeNode<T> left;
-
- /// <summary>
- /// Reference to the right child of the node.
- /// </summary>
- private BinaryTreeNode<T> right;
-
- /// <summary>
- /// Initializes a new instance of the BinaryTreeNode class. Sets the value to be held by the node. The childs and the parent references are set to null.
- /// </summary>
- /// <param name="theValue">The value to be held by the node.</param>
- public BinaryTreeNode(T theValue)
- {
- this.Value = theValue;
- this.Parent = this.Left = this.Right = null;
- }
-
- /// <summary>
- /// Initializes a new instance of the BinaryTreeNode class. Sets the value held by the node as well as the left and right child.
- /// </summary>
- /// <param name="theValue">The value held by the node.</param>
- /// <param name="left">The left child of the node.</param>
- /// <param name="right">The right child of the node.</param>
- public BinaryTreeNode(T theValue, BinaryTreeNode<T> left, BinaryTreeNode<T> right)
- {
- this.Value = theValue;
- this.Left = left;
- this.Right = right;
- }
-
- /// <summary>
- /// Gets a value indicating whether the node is a left child node.
- /// </summary>
- public bool IsLeftChild
- {
- get
- {
- return this.Parent != null && this.Parent.Left == this;
- }
- }
-
- /// <summary>
- /// Gets a value indicating whether the node is a right child node.
- /// </summary>
- public bool IsRightChild
- {
- get
- {
- return this.Parent != null && this.Parent.Right == this;
- }
- }
-
- /// <summary>
- /// Gets or sets the value to be hold in the node
- /// </summary>
- public T Value
- {
- set;
- get;
- }
-
- /// <summary>
- /// Gets or sets the left node of the node. The sette takes care of setting the proper parent-child relationship.
- /// </summary>
- public BinaryTreeNode<T> Left
- {
- get
- {
- return this.left;
- }
-
- set
- {
- if (this.left != null && this.left.Parent == this)
- {
- this.left.Parent = null;
- }
-
- this.left = value;
-
- if (this.left != null)
- {
- this.left.Parent = this;
- }
- }
- }
-
- /// <summary>
- /// Gets or sets the right node of this node. The sette takes care of setting the proper parent-child relationship.
- /// </summary>
- public BinaryTreeNode<T> Right
- {
- get
- {
- return this.right;
- }
-
- set
- {
- if (this.right != null && this.right.Parent == this)
- {
- this.right.Parent = null;
- }
-
- this.right = value;
-
- if (this.right != null)
- {
- this.right.Parent = this;
- }
- }
- }
-
- /// <summary>
- /// Gets the parent of node of this node.
- /// </summary>
- public BinaryTreeNode<T> Parent
- {
- get; private set;
- }
-
- /// <summary>
- /// Returns an enumerator that iterates through the collection.
- /// </summary>
- /// <returns>
- /// A <see cref="T:System.Collections.Generic.IEnumerator`1" /> that can be used to iterate through the collection.
- /// </returns>
- public IEnumerator<T> GetEnumerator()
- {
- throw new System.NotImplementedException();
- }
-
- /// <summary>
- /// Returns an enumerator that iterates through a collection.
- /// </summary>
- /// <returns>
- /// An <see cref="T:System.Collections.IEnumerator" /> object that can be used to iterate through the collection.
- /// </returns>
- System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
- {
- throw new System.NotImplementedException();
- }
- }
- }
Det meste af koden er ligetil. Der er to konstruktører. Den ene bruges til at sætte både den data der gemmes i elementet samt dens børn. Den anden gemmer kun data i elementet, mens dens børn og dens forælder sættes til
null.
I koden der sætter både venstre og højre barn, sikrer vi at de nye børns referencer til deres forælder er sat rigtigt; dette er meget vigtigt for at bevare træets konsistens. Derudover sørger vi for at et eventuelt tidligere barns forælder reference sættes til
null (hvilket betyder at vi fjerner et enkelt element, eller muligvis et helt undertræ fra træet).
Jeg har valgt også at implementere
IEnumerable<T>. Idden er at man kan starte en iteration gennem et undertræs elemtner ved at kalde
GetEnumerator() på undertræets rod. Indtil videre kastes blot en
System.NotImplementedException, men jeg vender tilbage til det senere i artiklen.
Implementation af BinaryTree<T>
Nu hvor vi har vores implementation af elementerne færdig (på nær vores "enumerators"), kan vi gå igang med at kode en klasse, som jeg vil kalde
BinaryTree<T>, der implementerer vores
IBinaryTree<T>-interface.
Det er gennem denne klasse at man arbejder med træet. Dens forskellige metoder gør dette ved at manipulere tre datamedlemmer af typen
BinaryTreeeNode<T>: en der repræsenterer træets rod, en der repræsenterer den nuværende knude, dvs. den knude som man er nået til under en "gennemgang" af træet (dvs. vores markør), og til sidst en reference til den knude som markøren pegede på før den eventuelt vandrede ud af træet. Disse tre datamedlemmer er helt centrale i implementationen af træet. Her følger koden:
- using System;
- using System.Collections;
- using System.Collections.Generic;
-
- namespace Trees
- {
- public class BinaryTree<T> : IBinaryTree<T>
- {
- private BinaryTreeNode<T> root;
- private BinaryTreeNode<T> cursor;
- private BinaryTreeNode<T> prior;
- private bool wentLeft;
-
- public BinaryTree()
- {
- this.Clear();
- }
-
- public IEnumerator<T> GetEnumerator()
- {
- return this.root.GetEnumerator();
- }
-
- IEnumerator IEnumerable.GetEnumerator()
- {
- return this.GetEnumerator();
- }
-
- public bool IsValid
- {
- get
- {
- return this.cursor != null;
- }
- }
-
- public T Value
- {
- get
- {
- return this.cursor.Value;
- }
- set
- {
- this.cursor.Value = value;
- }
- }
-
- public bool HasLeftChild
- {
- get
- {
- return (this.cursor != null) && (this.cursor.Left != null);
- }
- }
-
- public bool HasRightChild
- {
- get
- {
- return (this.cursor != null) && (this.cursor.Right != null);
- }
- }
-
- public bool HasParent
- {
- get
- {
- return (this.cursor != null) && (this.cursor.Parent != null);
- }
- }
-
- public bool IsLeftChild
- {
- get
- {
- return (this.cursor != null) && this.cursor.IsLeftChild;
- }
- }
-
- public bool IsRightChild
- {
- get
- {
- return (this.cursor != null) && !this.cursor.IsLeftChild;
- }
- }
-
- public bool IsEmpty
- {
- get
- {
- return this.Size == 0;
- }
- }
-
- public int Size { get; private set; }
-
- public void MoveLeft()
- {
- this.prior = this.cursor;
- this.wentLeft = true;
- this.cursor = this.cursor.Left;
- }
-
- public void MoveRight()
- {
- this.prior = this.cursor;
- this.wentLeft = false;
- this.cursor = this.cursor.Right;
- }
-
- public void MoveUp()
- {
- this.prior = null;
- this.cursor = this.cursor.Parent;
- }
-
- public void Insert(T value)
- {
- if (this.cursor != null)
- {
- throw new NotSupportedException("Cannot insert if cursor is not null");
- }
-
- if (this.prior == null)
- {
- if (this.root != null)
- {
- throw new NotSupportedException("Cannot insert at root in an non-empty tree");
- }
-
- this.cursor = this.root = new BinaryTreeNode<T>(value);
- }
- else
- {
- if (this.wentLeft)
- {
- this.prior.Left = this.cursor = new BinaryTreeNode<T>(value);
- }
- else
- {
- this.prior.Right = this.cursor = new BinaryTreeNode<T>(value);
- }
- }
-
- this.Size++;
- }
-
- public T Remove()
- {
- if (this.cursor == null)
- {
- throw new NotSupportedException("Node must exist in order to be removed.");
- }
-
- if (this.HasLeftChild || this.HasRightChild)
- {
- throw new NotSupportedException("Can only remove a leaf node, but the node you're trying to remove is a parent node.");
- }
-
- var value = this.cursor.Value;
-
- if (this.IsLeftChild)
- {
- this.MoveUp();
- this.cursor.Left = null;
- }
- else if (this.IsRightChild)
- {
- this.MoveUp();
- this.cursor.Right = null;
- }
- else
- {
- this.root = this.cursor = this.prior = null;
- }
-
- this.Size--;
- return value;
- }
-
- public void Clear()
- {
- this.root = null;
- this.cursor = null;
- this.prior = null;
- this.Size = 0;
- this.wentLeft = false;
- }
-
- public void Reset()
- {
- this.cursor = this.root;
- this.prior = null;
- this.wentLeft = false;
- }
- }
- }
Endnu et vigtigt datamedlem er
wentLeft som er en boolsk variabel som sættes til sannd såfremt markøren "vandrede" væk fra træet ved at gå til venstre. På denne måde kan vi i
Insert(T value) finde ud af om den nye knude skal være et venstre eller højre barn.
I konstruktøren kalder vi
Clear() som "nulsætter" hele træet. Bemærk at der er forskel på
Clear() og
Reset(). Hvor den første sletter hele træet og fjerner alle dets knude så et nyt kan opbygges, så sletter
Reset() intet, men flytter blot markøren tilbage til roden.
I
Remove() fjerner vi den bladknude som markøren peger på. Hvis markøren ikke peger på en bladknude kastes en
NotSupportedException.
Metoderne
MoveUp,
MoveLeft og
MoveRight bruges til at flytte markøren rundt i træet. Koden i metoderne sørger for at datamedlemmerne er korrekt sat.
De to
GetEnumerator metoder kalder blot samme metode på træets rod (som jo er af typen
BinaryTreeNode<T> der også implementerer
IEnumerable<T>-interface).
Resten af koden, som er properties, er ligetil og bruges til at undersøge træets topologi.
Nu er det tid til at kigge på iteration gennem træet. Vi skal implementere en enumerator. Faktisk skal vi implementere flere da der er flere måder hvorpå man kan iterere gennem et binært træ. Så lad os kigge på det.
Hvad synes du om denne artikel? Giv din mening til kende ved at stemme via pilene til venstre og/eller lægge en kommentar herunder.
Del også gerne artiklen med dine Facebook venner:
Kommentarer (4)
Nu har jeg godt nok aldrig kodet i C# før men den kode der virker på som alt for lang til en implementation af binær træer.
Og så bliver jeg lige nød til at spørge hvordan den der insert skulle virke for hvis jeg kaldte insert 2 gange på et tomt træ ville jeg efter min overbevisning få en exception smidt i hovedet, eller forestille du dig at man selv skulle sidde og rykke rundt med move funktionerne til man fandt en node med frie børn?
Hej Nørden.
Insert indsætter en knude i et tomt træ. Man flytter så markøren ud af træet v.h.a. MoveLeft og MoveRight, og kalder da Insert.
Måske ville det være på sin plads med et eller flere kode eksempler på hvordan du forestiller dig man rent faktisk brugte din kode.
Tror ikke at jeg er den eneste der ville få problemer med at bruge det
")
.
Du kunne f.eks lave eksempler på hvordan man bygger træet, sletter i det og bruger en eller flere af de der iteratorer, men det bare et forslag.
PS så synes jeg det en god artikel, men hvis du kan rette i den burde du evt, lave en eller flere(en per fil) bokse med all koden i tilsidst, ville gøre det lettere at kopier den.
Hej Nørden.
Det har du helt ret i. Det gik op for mig da jeg læste din kommentar at jeg skulle have tilføjet et eksempel på brug af koden. En åbenlys mangel. Jeg vil opdatere artiklen med et eksempel inden længe.
Tak for kommentarene.
Du skal være
logget ind for at skrive en kommentar.