
15

Tags:
database
locking
timestamping
samtidighed
transaktion

Skrevet af
Bruger #4487
@ 23.08.2011
Serialisering af dine transaktioner
Nu har vi gennemgået nogle af de problemer, som der kan ske ved samtidige transaktioner. Vores DBMS har selvfølgelig nogle protokoller, der skal sørge for at disse problemer ikke opstår. En af måderne vi kan sørge for at disse problemer med samtidige transaktioner ikke opstår, er ved at køre transaktionerne serielt. At køre transaktionerne serielt, betyder at hver transaktion lægges ud i en lang kø, alt efter hvornår vores DBMS modtog dem, og herefter gennemfører transaktionerne en af gangen. Lad os f.eks. sige at vi har tre transaktioner, der kommer ind stort set samtidigt (i menneskeøjne samtidigt, men i computerøjne adskilt med nanosekunder). Vores DBMS lægger nu de tre transaktioner i kø, hvor den der kom ind først, også bliver nummer et i køen. Vores DBMS sætter nu de to andre i 'vente' position, indtil det bliver deres tur. Dette sikrer jo at vores transaktionerne ikke kan køres samtidigt, altså at vi kører en transaktion ad gangen. Du har sikkert allerede oplevet denne form for struktur allerede. Tænk bare når du ringer til SKAT, så er den først meddelelse du får ikke 'Hej, mit navn er Thomas, hvad kan jeg gøre for dig', men nærmere 'Du er nummer 4 i køen... Vent Venligst'. Dette er en seriel struktur der anvendes her, hvor du først kommer til, når der bliver en ledig medarbejder. Umiddelbart lyder dette som løsningen på vores problemer, men der er en stor ulempe ved at køre alle sine transaktioner serielt. Ulempen er at hvis der er virkelig mange transaktioner, og en del af dem måske oven i købet skal løse en masse operationer, så vil det tage lang tid for de enkelte transaktioner at komme igennem, og det vil selvfølgelig nedsætte brugeroplevelsen, eller måske endda få et firma til at tabe penge, fordi man spilder unødig tid. Tænk også bare på googles millioner af brugere, hvor en lille håndfuld søger på de samme data samtidigt. Tænk hvis de skulle vente på at de fik lov til at læse dataende fra en af googles servere. Mange af disse brugere ville hurtigt have surfet videre til en anden søgemaskine for at finde sine oplysninger. Der findes derfor også noget der hedder en
interleaved serialisering, som også er en seriel tilgang til at køre transaktionerne. Når det er en interleaved serialisering, så laver den en bid af den første transaktion, hvorefter den laver en bid af den anden transaktion, hvor den så vender tilbage til den første, og måske færdiggør denne, for til sidst at færdiggøre den anden. Illustrativt kan man vise de to serialiseringer således, hvor den øverste del viser tre transaktioner der køres serielt, og den nederste del viser de samme tra kørende med en interleaved serialisering:
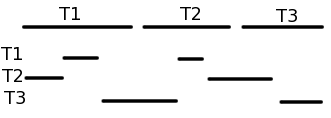
Problemet vender så tilbage med den interleaved serialisering, fordi en transaktion kan være i gang med opdatering af data, som en anden transaktion også bruger. Så den ultimative løsning er at have transaktionerne som en almindelig serialisering, men dette gjorde jo at hvis vi havde mange transaktioner, så tog det lang tid at få sin forespørgsler igennem i databasen. Så hvordan benytter databasen så interleaved serialisering, men samtidig sikrer at vi ikke overskrider vores ACID principper? Jo, vores DBMS skal have nogle protokoller at arbejde med, som den kan bruge til at sikre at en transaktion er udført serielt, selvom at den faktisk er udført interleaved. En af de protokolsfremgangsmåder der findes, og som faktisk også er en af de allermest brugte protokol metoder, kaldes for
locking. Vi skal i de næste afsnit høre om locking protokollerne og hvordan de virker.
Locking
Locking virker på den måde at man låser det som brugeren har gang i/arbejder med, sådan så andre transaktioner der forsøger at arbejde med det samtidigt, må vente til vores første transaktion har låst vores data op. Det siger lidt sig selv i ordet locking (låsning), at man låser noget af ens database, ja i teorien kan man låse hele databasen, men dette vil være spild af ressourcer, og ville ikke lade transaktionerne kunne arbejde interleaved. Det mest normale er at vores DBMS låser de rækker/data felter som vores transaktion skal arbejde med.
Man kan sige at der findes flere forskellige måder at låse data på, og en af dem er det som man kalder den
binære låsemetode (Eng.: Binary Locking). Denne metode består i at enten er vores række låst for alle andre rækker eller også er den låst op. Deraf kommer navnet binær, fordi der kun er to valgmuligheder for vores transaktioner, enten er det dig der har adgang, ellers må du vente til det bliver din tur til at tilgå dataende. Vi kan prøve at opstille den binære låsemetode i en simpel algoritme, som vores DBMS kunne tænkes at bruge (Ikke at den bruger lige præcis denne algoritme, men bare at vi kan se et eksempel på hvordan vores DBMS kunne arbejde med denne låsemetode).
Algoritme, når en transaktion vil låse noget data.
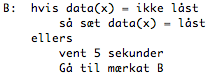
Som vi kan se, så tjekker denne algoritme om vores data(x) ikke er låst. Hvis dette er tilfældet, skal den låse vores data, ellers skal den vente lidt og prøve igen. Ligeledes bruger vores DBMS en algoritme til at låse data op, og den er mindst ligeså simpel.
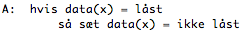
Her vil algoritmen bare låse vores data op, hvis den er låst, altså en algoritme vores DBMS vil bruge, når den skal 'unlocke' vores data, så andre transaktioner kan få adgang til det. Denne binære låsemetode er meget restriktiv, og derfor meget tidskrævende. F.eks. hvis transaktion 1 er inde og læse noget data i en række, så må transaktion 2 pænt vente, selvom denne transaktions ønske også kun er at læse data. Man kan sige at der jo ikke er nogen grund til at låse data for alle andre transaktioner, hvis deres eneste formål er at læse data, men ikke opdatere. Derfor taler man om noget der hedder
læse/skrive låsningsmetoden (Eng.: Read/Write Locks).
Når man benytter read/write locks, betyder det at man har to forskellige låsemetoder. En der hedder read lock og en anden der sjovt nok hedder write lock. Forskellen på disse to låsemetoder er at read lock er en delt låsemetode, mens write lock virker som en binær låsemetode. Lad os se på hvordan algoritmen på en read lock kunne se ud.

Som man kan se, tjekker den om vores data overhovedet er låst. Hvis ikke den er det, så lås den med en read lock, og opret en tæller der har en startværdi på 1. Ellers hvis data(x) er read locked, så giv adgang og opdater tælleren med 1. Hvis ingen af de to betingelser er opfyldt, er det en fordi vores data er blevet write locked, og en write lock er som sagt ikke en delt låsemetode. Lad os nu se på hvordan vores write lock algoritme ville virke.
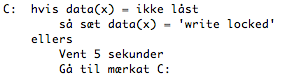
Når vi vil lave en write lock, så skal vores DBMS først tjekke om vores data er låst, hvis ikke dette er tilfældet, så tillad transaktionen og lav en write lock på vores data. Ellers sæt vores transaktion i en vente position, som vi har set det tidligere. Til sidst er der jo vores 'unlock' algoritme, der i dette tilfælde er lidt mere kompliceret, da vi jo har at gøre med en delt låsemetode, når vi har lavet en read lock. Lad os se på algoritmen først.

Her vil vi først tjekke om data er låst med en write lock. Hvis dette er tilfældet, så 'unlock' data og sæt den til ikke låst. Hvis data derimod er låst med read lock, skal vi først tjekke om der er flere læsere der benytter vores data. Husk på at read lock er delt. Hvis der ikke er flere læsere (tæller = 0), så sæt data til ikke låst.
Det smarte med read/write locks er som du forhåbentlig har fundet ud af nu, at read lock tillader brugeren at dele data med andre, så længe deres intentioner er at læse, hvorimod write lock kun tillader en transaktion ad gangen, til at arbejde med data. Tænk f.eks. på google's servere. Der kan være flere hundrede og tusinde mennesker der søger på søgeordet programmering. Google's database skal så vise de samme informationer til alle hundrede tusinde mennesker, på samme tid. Med den binære låsemetode ville hver enkelt person skulle vente på at hver transaktion var færdig. Dette betyder at der kunne opstå en mindre ventetid, før du måske fik dit data vist. Med en read/write lock, vil data blive vist meget hurtigere, da du kun læser fra googles database, og derfor deler din lock med alle de andre der søger på det samme som dig, på samme tid.
Optimistisk og Pessimistisk låsning
Der findes også 2 andre låsemetoder, kaldet
optimistisk og
pessimistisk låsning (Eng.: Optimistic & Pessimistic Locking). Optimistisk låsning har den teori at transaktioner som udgangspunkt ikke vil gå i konflikt med en anden transaktion. Hvis dette dog skulle ske, så skal vores DBMS lave en rollback, på de involverede transaktioner. Pessimistisk låsning virker stort set modsat. Den har nemlig en teori om at transaktionen, på et eller andet tidspunkt, vil komme i konflikt med en anden transaktion, derfor skal den låse så meget den kan, så hurtigt som muligt. Man kan sige at den optimistiske teori fokuserer på at samtidige transaktioner bare skal tage det stille og roligt, og hvis der sker en fejl, så løser vi den ved at prøve igen, hvorimod at den pessimistiske teori fokuserer på at transaktioner skal gøre sig selv så sikre som overhovedet muligt, da en rollback løsning kun skal ses som den ultimative sidste løsning. De fleste hælder til den pessimistiske teori, da den syntes mere sikker, men den optimistiske teori øger databasens performance, da den ikke bruger ligeså mange ressourcer på at låse, samtidig med at den ikke behøver at sikre sig med låsning af alt, da chancen for fejl i mellem to transaktioner er minimal.
Two Phased Locking
En af de sidste låsemetoder der findes er en der er kaldt
Two Phased Locking (Da.: To fase låsning). Teorien bag denne metode er at vores transaktions opgaver er delt op i to faser. Den første fase kaldes for gro fasen (Eng.: Growing Phase), fordi formålet er at transaktionen får låst og brugt de data den har brug for. Den anden fase kaldes så for krympe fasen (Eng.: Shrinking Phase), og formålet med denne fase er at låse alle de data op som vores transaktion tidligere har fået låst. Grunden til de to faser er, at man i gro fasen kun, og jeg mener kun, låser de data som man skal bruge. Så snart man begynder at låse data op, går man automatisk ind i fase 2. Når man er i fase 2 må man kun, og jeg mener kun, låse data op, aldrig låse ny data. Dette er teorien for 'Two Phased Locking', og grunden til at man har udviklet denne teori, er at de andre låsemetoder faktisk ikke ordentligt beskytter imod de problemer som vi allerede har kigget på, såsom lost update etc. Når man benytter 'two phased locking' sikres vi ordentligt i mod disse problemer. Til gengæld opstår et byt problem der er kendt under navnet
deadlock. Dette kan vi kigge lidt på nu.
Deadlock
En af de problemer der ikke løses af nogle af vores hidtil nævnte metoder, er det som man kalder for
deadlock. En deadlock betyder at vores database transaktioner går i selvsving, og venter på at noget data bliver låst op, men dette sker aldrig. Hvorfor det aldrig sker, kan vi se ved at lille eksempel, husk at det hele sker samtidigt.
- Jesper låser række A
- Sara låser række B
- Jesper forsøger at tilgå række B, men kommer i vente position
- Sara forsøger at tilgå række A, men kommer i vente position
Hvis ikke vores DBMS registrerede dette, ville Jesper og Sara vente i uendelighed, eller hvert fald til en af dem annullerede deres forespørgsel. Sara og Jesper har nu oplevet en deadlock. Måden vores DBMS løser dette på, er ved at overvåge hvor lang tid transaktioner venter på andet data, og hvis der er gået længe nok, så laver vores DBMS et rollback på en af vores transaktioner, som så for lov at starte forfra. Det er den eneste og nemmeste måde at løse en deadlock på.
Nu har vi gennemgået locking protokollerne, og dette er en af de mest almindelige og mest anvendte protokoller i et DBMS, men der findes en anden måde at løse de i starten omtalte problemer. Løsningen kaldes for
timestamping, og den skal vi også hurtigt kigge på.
Timestamping Protokol
Timestamping er en anden måde at håndtere transaktioner på, og derved sikre at ens database ikke bliver inkonsistent. Et timestamp er en unik værdi, som hver transaktion får tildelt, som vores DBMS så kan bruge til at tjekke hvilken transaktion der er nyest. Bemærk at et timestamp ikke nødvendigvis er et 'tidsstempel', men bare en unik værdi, som ens DBMS kan bruge til at finde ud af hvilken der transaktion der er nyest. I vores eksempel nedenfor vil vi benytte timestamp som tid, da dette er nemmest for os at forstår, når vi skal finde ud af hvad der er nyest.
Timestamping virker altså på den måde at hver transaktion bliver givet et unikt timestamp, som bliver brugt af vores DBMS. Vi slipper derfor for at låse vores rækker/data, fordi vores DBMS vil udføre transaktionerne i en rækkefølge der er stillet op efter hvilket timestamp der er ældst til nyest. Lad os se på et eksempel.
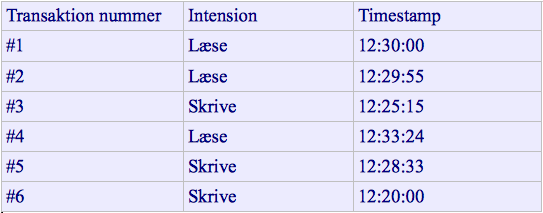
Her har vi en liste af nogle transaktioner der er blevet kørt samtidig, og timestampet der er tilknyttet til hver transaktion er i vores eksempel skrevet som en tid, da vi så ved hvilken tid der er nyest, og dette er nemmere at forholde os til. Når man snakker om timestamping, har man to forskellige intentioner, nemlig enten at læse eller at skrive. Hver intention har deres egen 'log', hvilket betyder at de har to forskellige timestamp 'saving points'. Lad os prøve at gå ind i eksemplet, for at se hvad det er der virkelig sker.
Transaktion #1 forsøger at læse vores række og for tildelt timestampet 12:30:00. Dette timestamp bliver gemt under vore RTS (Read Timestamp). Transaktion #2 forsøger at læse vores række og tildeles timestampet 12:29:55. Det tidligst gemte RTS var 12:30:00 og dette er derfor nyere end 12:29:55, hvilket betyder at transaktion #2 oplever et rollback og for derfor tildelt et nyt timestamp, og lagt nederst i vores liste. Herefter prøver transaktion #3 at skrive og får derfor timestampet 12:25:15. Dette bliver også gemt til vores WTS (Write timestamp). Transaktion #4 Forsøger nu at læse og for tildelt timestampet 12:33:24. DBMS'et tjekker nu om Transaktion #4's timestamp var nyere end det tidligst gemte RTS. Vores RTS var 12:30:00 og derfor er Transaktion #4's timestamp nyere, og den får derfor adgang til vores række. Vores RTS bliver nu opdateret til 12:33:24. Transaktion #5 forsøger nu at skrive til rækken, og får timestampet 12:28:33. Da dette er nyere end hvad vi sidst gemte i WTS (12:28:33), får vores transaktion #5 lov til at skrive til rækken. Transaktion #6 vil nu også skrive til rækken, og får timestampet 12:20:00, men bliver afvist da timestampet er ældre end hvad der var sidst gemt i vores WTS. Transkation #6 oplever derfor et rollback og får et nyt timestamp.
Timestamping er stadig ikke ligeså udbredt som locking, men er en af de metoder der vinder ind. Timestamping får nemlig transaktionerne til at opføre sig serielt, selvom de er interleaved, uden at behøve og låse dem. Hvilken metode der er bedst vil jeg ikke gøre mig klog på, da mange mener at locking stadig har en masse fordele, som timestamping ikke har, og omvendt.
Nu ved du en del om hvordan vores DBMS arbejder, og hvilke problemer den står overfor og hvordan den kan løse dem. Selvom at artiklen her ikke har andet end 'teoretisk' indhold, håber jeg at du når du skal ud at programmere systemer og applikationer, har en hel del mere med i rygsækken angående om hvordan databaser fungerer og virker.
Hvad synes du om denne artikel? Giv din mening til kende ved at stemme via pilene til venstre og/eller lægge en kommentar herunder.
Del også gerne artiklen med dine Facebook venner:
Kommentarer (2)
Fantastisk arbejde Martin, du har været med til at gøre min eksamens opgave lidt det bedre
")
.
Det er jeg glad for at du syntes
(Undskyld det lidt sene svar

)
Du skal være
logget ind for at skrive en kommentar.